102各种问题
1.你们本地部署大模型具体的配置 参数是怎样的
我们本地部署的是 Ollama + DeepSeek-R1 7B 的组合,主要作为审核和情感分析模型使用。
部署环境是:
8 核 CPU + 32G 内
一块 3090 24G 显存的 GPU —–显卡的型号
Ollama 启动参数中配置:
num_gpu: 1
num_ctx(上下文长度): 4096(保证标题、简介字段能完整输入)
num_thread: 自动(由 Ollama 自动根据 CPU 核数分配)
我们通过 Spring AI 统一封装模型调用,使 Camunda 的 JavaDelegate 能够直接调用审核接口
2.ai审核只能审核短剧标题和简介吗,不能审核短剧内容吗
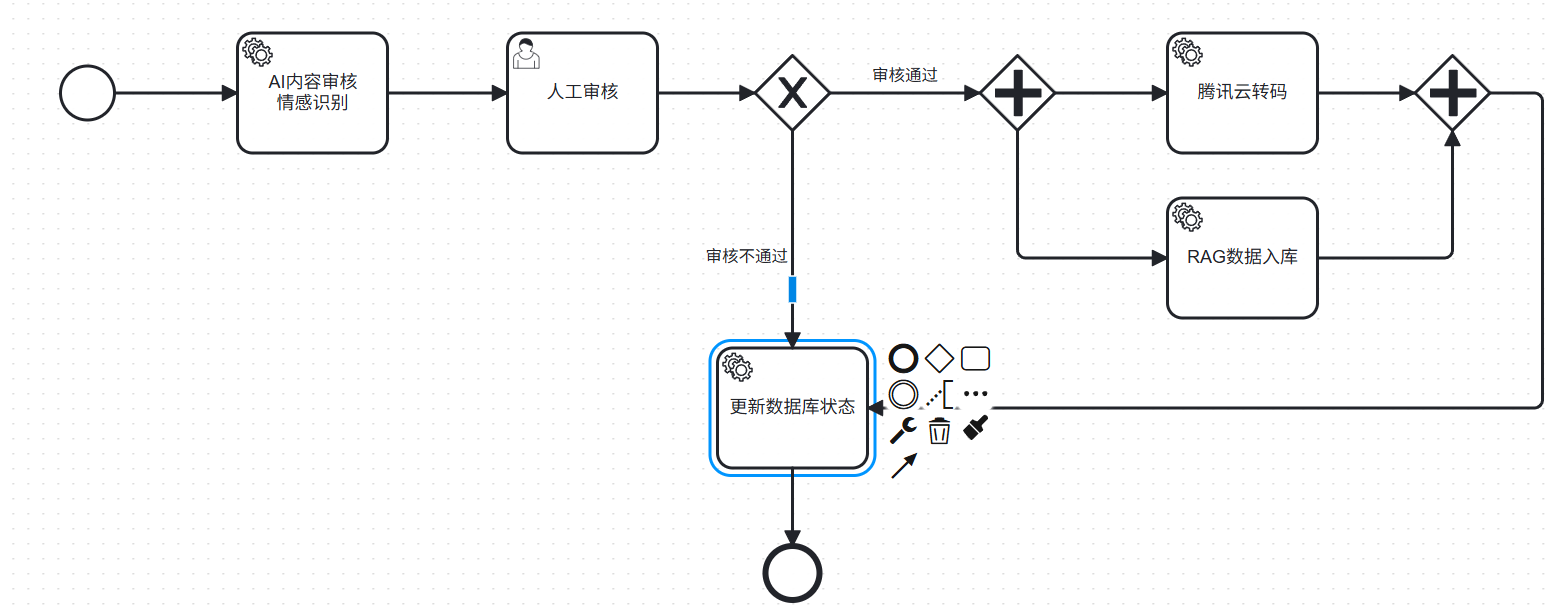
视频内容审核属于多模态识别,需要视频帧抽取、ASR、行为识别,这部分我们没有在本地做,因为算力成本太高。
我们的 AI 审核分两层:
1,文本审核(本地模型)
标题、简介、标签
情感分析、涉政涉黄、违规用语
2,视频内容审核(外部平台)
通过腾讯云 VOD 的内容审核能力,它会:
自动抽帧
识别黄暴、暴力、广告等内容
审核回调直接进入 Camunda 流程
因此我们的审核对标题/简介/图片/视频内容都是覆盖的,只是负责的模块不一样。
3.你说你们是多租户,是怎么实现数据隔离的,a公司不能看到公司的数据吧
你的项目使用 Spring Cloud + 多租户平台,这里你这样回答:
我们的多租户采用的是数据库级隔离+应用级租户上下文的组合方案。
数据库层: 每张核心业务表都带 tenant_id 字段,MyBatis-Plus 通过自定义 TenantLineHandler 自动拼接
WHERE tenant_id = xxx
实现物理隔离数据。
应用层:
用户登录后,Sa-Token 中写入 tenantId
网关从 Token 解析后塞入请求头
下游服务通过 ThreadLocal 的 TenantContext 保存租户信息
MyBatis-Plus 自动替换租户 ID,不允许跨租户查询
我们还做了 缓存隔离:
Redis Key 前缀使用:
video:{tenantId}:{videoId}
保证缓存不串租户。
4 短信接口你们有做防刷吗
我们对短信验证码做了三层防刷策略:
频控:
同手机号 60 秒只能发 1 次
同 IP 1 小时最多发 15 次
Redis 用 INCR + EXPIRE 实现
行为校验:
前端接入滑块验证码
黑名单池:
自动记录异常频繁请求的 IP/设备指纹
Redis + TTL 自动衰减
5.多次点击发布按钮,这一块有没有做什么安全措施
在短剧发布这种关键操作上做了两种幂等保护:
前端防重复点击:按钮 loading 状态锁定
后端防重复提交(核心):
使用 Redis 分布式锁
Key = publish:{tenantId}:{videoId}
TTL 设置 3 秒
这样同一用户连续点击多次发布,只会执行一次流程。
另外发布流程走 Camunda 工作流,本身也具备幂等校验,避免重复创建任务
6.miniio有没有做集群部署 是怎么实现上传的,有没有断点续传之类的
MinIO 我们做了两种部署策略:
开发环境:单节点 MinIO
生产环境:MinIO 4 节点分布式集群
EC(纠删码)为 4/2
//////////////使用 Nginx 负载均衡访问
上传流程使用的是 MinIO 官方的 Multipart Upload(分片上传) 接口:
大文件自动分片
支持断点续传
上传完成后自动合并块
我们这块会自动重试失败的 Part,因此对网络波动比较友好
为什么要模拟 robot 账号登录 XXL-Job?不能直接调任务吗?
为什么不直接调用 XXL-Job 的 openAPI?
为什么要登录一个模拟账号?
XXL-Job 的任务你们是怎么触发的?
参考话术
我们不是从 XXL-JOB 控制台页面触发,而是通过它的 OpenAPI 接口触发任务执行。
robot 账号只是为了权限隔离,便于区分是系统自动触发还是人工上传等操作触发。
我们不会模拟点按钮,而是直接发 trigger/run API 调任务。
单机 Map 保存审核结果,会不会有线程安全/多实例问题?
参考话术
Map 只在流程内部暂存,用于在同一Camunda 流程中传递,不用于跨节点通信。
需要跨任务传递的,我们会放到 Camunda 流程变量 或 Redis。
所以不会出现安全数据的问题。
本地大模型审核 + 腾讯云视频审核,如果其中一个失败怎么办?
如果大模型审核失败了呢?
如果腾讯云审核回调延迟怎么办?
两个审核不一致怎么处理?
参考话术:
我们的审核采用 容错 + 兜底策略:
本地大模型异常–>走默认人工审核
腾讯云视频审核异常–>XXL-Job 会自动重试
两者冲突–>统一流入人工审核节点
不会出现审核中断的情况。
审核流程为何使用 Camunda?可不可以不用?
参考话术:
视频审核是一个多阶段的流程:
AI审核–>视频内容审核–>人工审核–>审核结果汇总
使用 Camunda 的目的是:
把复杂流程可视化
状态和节点可追溯
人工审核可以暂停/回退
多个审核结果汇总更清晰
如果不用工作流,自己维护状态机会非常混乱。
XXL-Job 触发腾讯云上传任务,这里有没有幂等问题?
最常问:
如果重复触发,视频会不会被上传两次?
话术:
我们做了两层幂等:
XXL-Job 任务使用业务 Id 作为参数,任务重复触发不会重复执行
腾讯云 VOD 上传使用唯一的 fileId,同一个源文件上传两次也不会重复转码
所以整体流程是天然幂等的。
腾讯云回调是怎么和工作流衔接的?
回调怎么通知 Camunda?
有没有延迟?
如何保证一致性?
参考:
腾讯云审核是异步的,我们在回调接口里更新审核状态,并通过 Camunda 的 RuntimeService 唤醒对应流程实例。
如果回调超时,则自动进入人工审核节点。
消息幂等性保证
方案1: Redis Set记录已处理消息ID
1 | |
方案2: 数据库唯一索引 + 幂等更新
1 | |
最终一致性保证
流程:
- 用户点击点赞 → 发送Kafka消息 → 立即返回成功
- Kafka消费者1(user-service)→ 更新Redis缓存
- Kafka消费者2(interaction-service)→ 更新数据库
- 消息持久化 + 手动ACK → 保证消息不丢失
- 幂等性处理 → 重复消费结果一致
优势:
- 降低接口响应时间(异步处理)
- 削峰填谷(高并发缓冲)
- 最终一致性(数据库与缓存同步)
双写一致性
用mq的手动ack机制确认,一个失败就不会ack
C. 常见问题FAQ
Q1: Kafka消息积压怎么办?
A: 增加消费者实例数、优化消费逻辑、增加分区数
Q2: Redis内存不足怎么办?
A: 设置合理的过期时间、使用LRU淘汰策略、扩容Redis节点
Q3: Camunda流程实例查询慢?
A: 定期归档历史数据、优化数据库索引、使用缓存
Q5: 布隆过滤器误判怎么办?
A: 降低误判率(增大内存)、配合缓存空对象使用
7.3 Kafka事件驱动架构
7.3.1 生产者拦截器(自动填充公共字段)
KafkaEventProducerInterceptor:
1 | |
效果: 业务代码只需构造核心业务字段,公共字段自动填充
7.3.2 消息幂等性保证
方案1: Redis Set记录已处理消息ID
1 | |
方案2: 数据库唯一索引 + 幂等更新
1 | |
7.3.3 最终一致性保证
流程:
- 用户点击点赞 → 发送Kafka消息 → 立即返回成功
- Kafka消费者1(user-service)→ 更新Redis缓存
- Kafka消费者2(interaction-service)→ 更新数据库
- 消息持久化 + 手动ACK → 保证消息不丢失
- 幂等性处理 → 重复消费结果一致
优势:
- 降低接口响应时间(异步处理)
- 削峰填谷(高并发缓冲)
- 最终一致性(数据库与缓存同步)
\
技术痛点
流程引擎负责推进流程的执行。流程引擎记录流程的执行历史;写代码可以永远只查询当前要做什么即可。
- 流程(PROCESS) : 通过工具建模最终生成的BPMN文件,里面有整个流程的定义
- 流程实例(Instance) :流程启动后的实例
- 流程变量(Variables) :流程任务之间传递的参数
- 任务(TASK) :流程中定义的每一个节点
- 用户任务:人工审核
- 系统任务:代码任务
- 流程部署 :将之前流程定义的
.bpmn文件部署到工作流平台
流程定义文件 ===> 部署工作流平台 ===> 请假v-emp版本部署 ===> v1部署一个流程实例
===> 请假v-leader版本部署 ===> v2部署一个流程实例
===> 请假v-hr版本部署 ===> v3部署一个流程实例
Process Engine -流程引擎
Web Applicatons - 基于web的管理页面
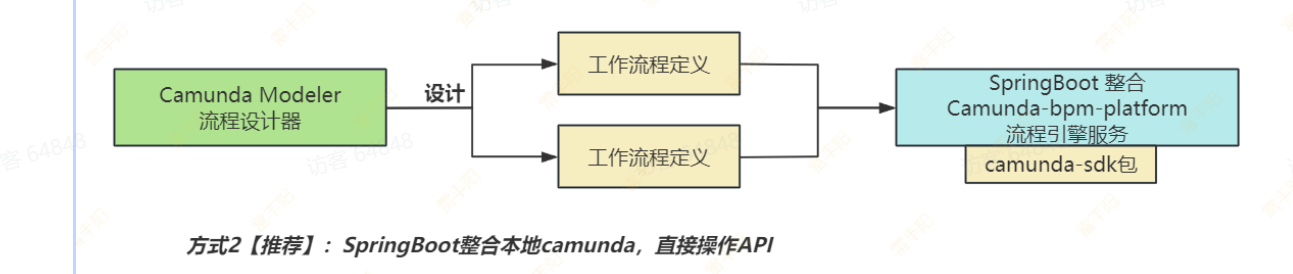
调用****流程引擎服务有三种方式**:
- 通过 Camunda Web 控制台界面
- 通过官方 rest 接口操作 camunda 流程引擎,Camunda Platform REST API 官方说明文档:Camunda Platform REST API
Java 代码调用 Camunda 提供的 Service 接口(如:org.camunda.bpm.engine.RuntimeService、org.camunda.bpm.engine.TaskService 等等)
https://docs.camunda.org/manual/latest/
1 | |
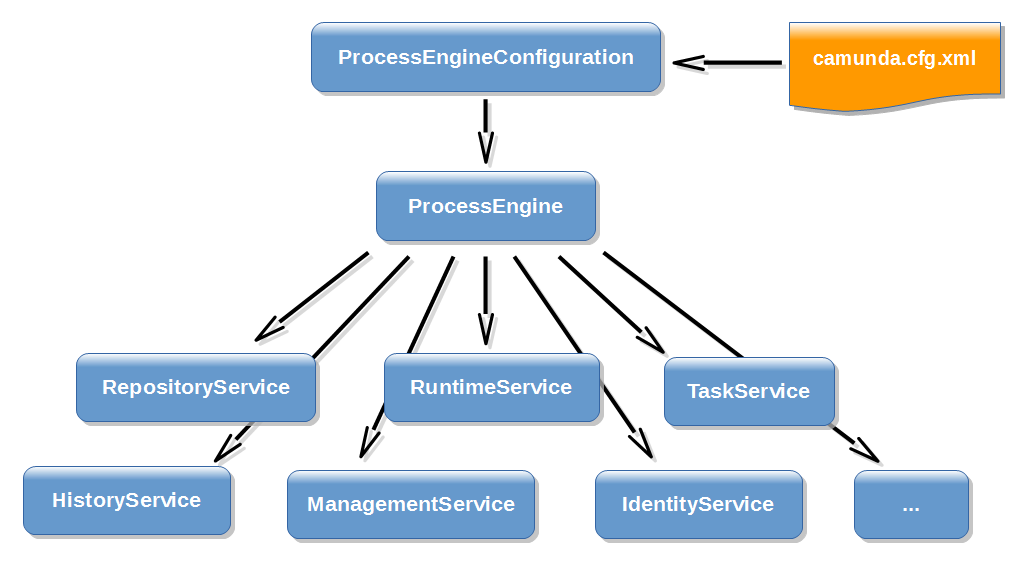
1RepositoryService
- 管理流程定义(BPMN)、部署、模板等静态资源(Definition 层)
- 主要负责部署流程、查询流程定义、读取模型文件等。
1 | |
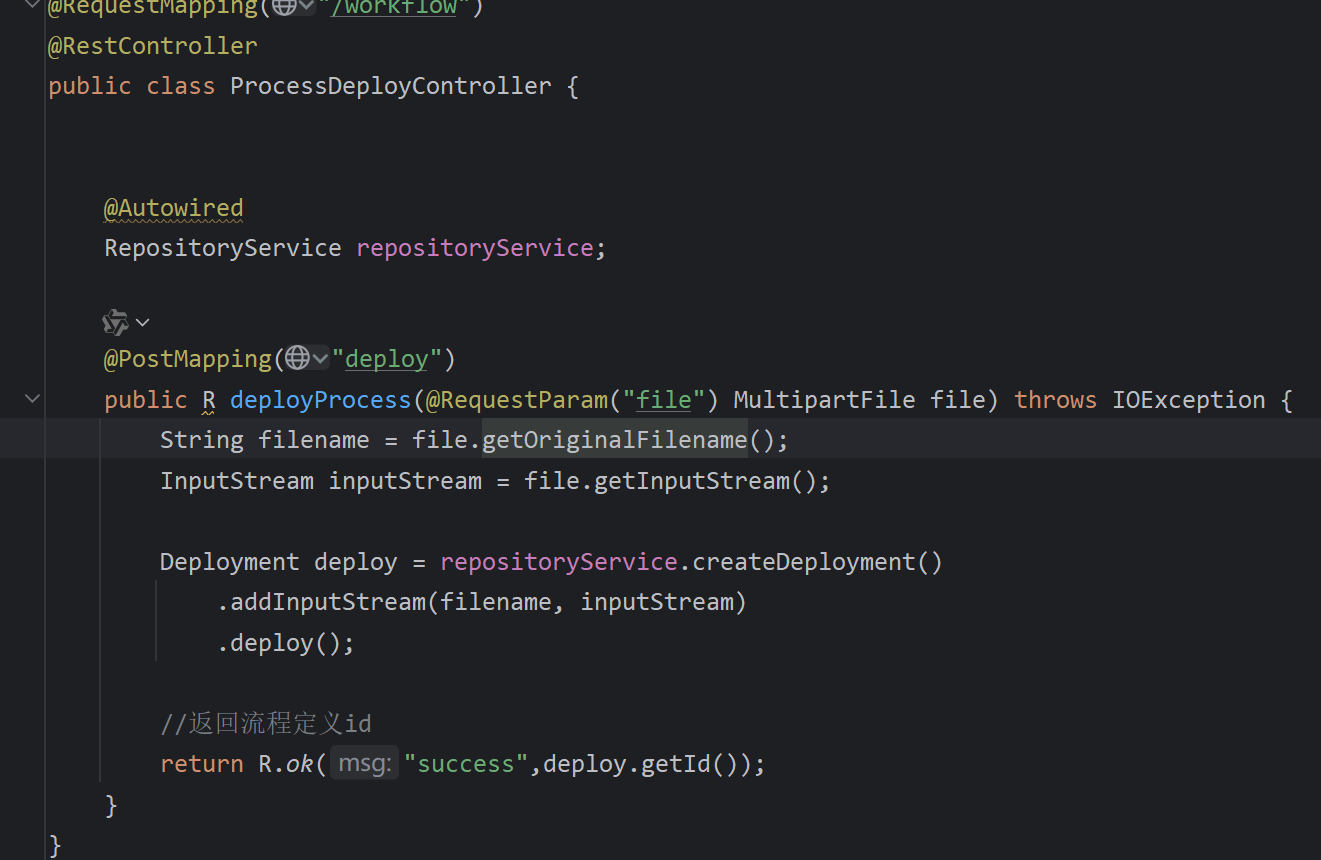
2保存远程调用
保存剧集信息,演员信息,基本信息,关联信息之后再

远程调用启动

3ai初审
1 | |
- 运行时管理流程实例(Instance 层)
- 启动流程、管理运行中的流程实例和执行对象(Execution)
- 设置与获取流程变量(Process Variables)
- 触发消息、信号、定时事件等。
1 | |
4人工初审

任务API
基于service的查询类,都可先构建一个 query,然后在附上查询条件
1 | |
1 | |
1 | |
5流程变量
包括流程中产生的变量信息,包括控制流程流转的变量,网关、业务表单中填写的流程需要用到的变量等。很多地方都要用到
变量最终会存在 act_ru_variable 这个表里面
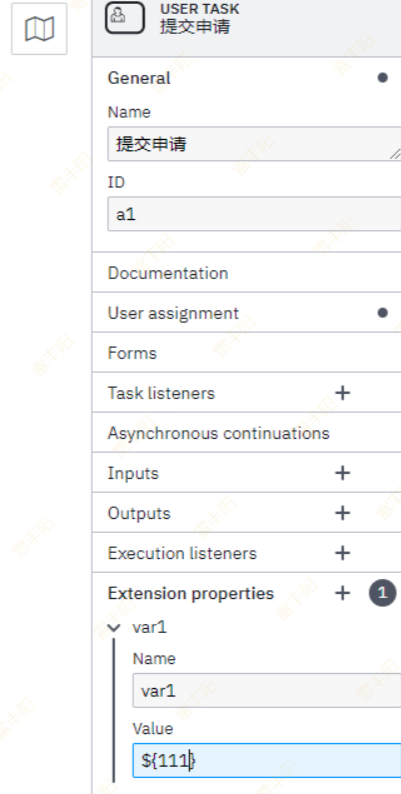
在绘制流程图的时候,如果是用户任务(userService) 可以设置变量,比如执行人,

- 写死,就比如 zhangsan
- 表达式,比如上面写的
${user},这种需要传入参数,其实就是启动参数的时候传入,传入参数,可选值为一个Map<String, Object>,之后的流程可查看次参数,上面写的是 user, 所以map里面的key需要带着user,不然会报错。
关于扩展变量,可在流程图绘制这么设定,传递方式还是一样,流程图里面在下面写:
启动流程:传入变量
1 | |
变量设置
1 | |
变量查询
1 | |
历史变量查询
1 | |
针对后端来说任务类型主要有两种。
用户任务-userTask
即需要用户参与的任务,因为工作流执行过程中需要涉及到审批、过审之类的需要用户参与的任务,这个时候需要用户参与,然后调用接口完成任务。
服务任务-serviceTask
即自动执行的任务,比如用户提交后,系统自动存储、修改状态等自动完成的任务。
任务类型是关键,可根据配型配置实现调用 java的方法,spring 的bean方法等等。有这么几种类型
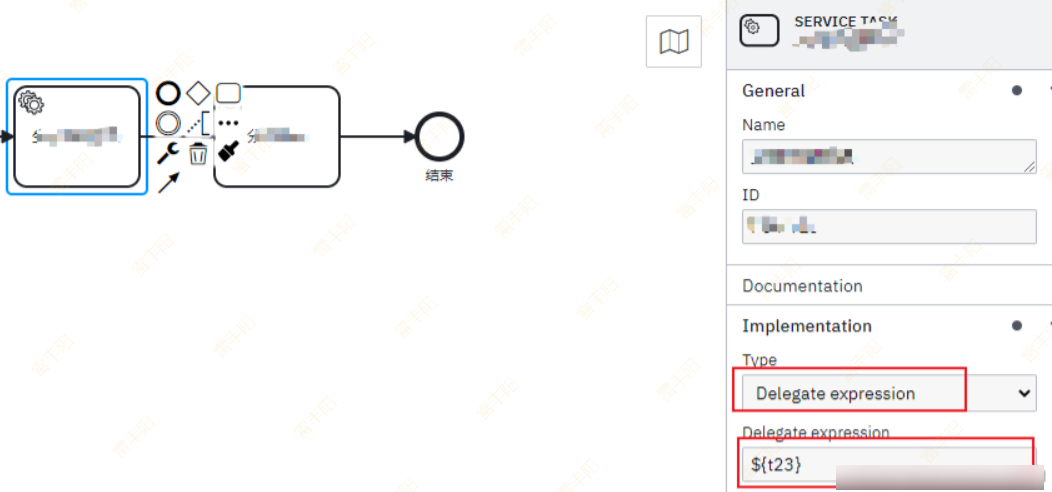
在系统任务中,因为是自动执行,所以实际应用中需要嵌入各种业务逻辑,可以在流程图设计中,按照下面方式调用java代码执行,在spring中配置同名的bean
@Bean
@Bean注解用于标记一个方法作为Spring的bean工厂方法。当一个方法被@Bean注解标记时,Spring会将该方法的返回值作为一个bean,并将其添加到Spring容器中,如果自定义配置,经常用到这个注解。
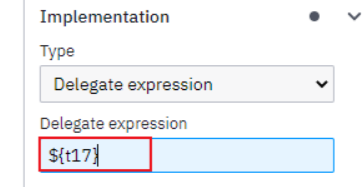
配置表达式,可以实现JavaDelegate接口使用类名配置
- 快捷写法如下,比较推荐下面这种,此种可灵活配置bean和spring结合使用,注入service等业务方法
1 | |
- **Java Class :**配置java类名,需要实现JavaDelegate接口,注意是全路径名,不可以使用Spring的bean配置!!!
1 | |
扩展: BPMN
BPMN:BPMN是由BPMI(The Business Process Management Initiative)开发的一套标准叫业务流程建模符号,于2004年5月对外发布了BPMN 1.0 规范。后BPMI并入到OMG组织,OMG于2011年推出BPMN 2.0标准,对BPMN进行了重新定义(Business Process Model and Notation)
面试
ollama 暴露的 API 接口地址。SPring AI直接可以调用。上线了。云GPU服务器。
各种模型调用、RAG、向量检索
模型幻觉(微调模型会有幻觉) ok,没问题
相似度算法、
温度高,输出不稳定。
了解 过 vllm 框架 能加速推理。不了解
每晚3点。短剧会全量缓存,预热。防止漏更新。 5000多短剧。为未来准备的
短剧每天都会增。
增量数据是靠kafka 消息,进行redis和数据库同步
并发多线程查询的,会提交线程池 submit 提交任务
CompletableFuture.runAsync()
allof() 返回所有结果
主键就是局促;叶子节点完整数据
其他就是非局促;叶子节点只有主键id
只查索引列数据即可。不写select *
从机 start slave 命令就可以。
- 主机开启 binlog 日志
- 从机连接主机。
- 从机开始同步获取binlog,并记录relay_log(中继日志)
- 从机重放 relay_log 内容
binlog同步到哪里有 记录position位置。
技术复杂度高,得搞一堆 注册中心、配置中心、远程调用、链路追踪等
基本不用,嫌不好维护
require_new
required
等 Synchronized (对象头锁标志位)
无锁 –> 偏向锁(一个线程在用所) –> 轻量(两个线程在用所【自旋获取锁】) –> 重量(更多线程在用所【等待唤醒机制获取锁】)
或者 Lock( AQS中的 state 属性, CLH队列(双向链表的队列)维护锁公平性 )
=================================
****基础的搜索:****直接走向量库搜索(Redis)、不走大模型
不断的新发短剧。新短剧进向量库。所有的搜索走向量库相似度搜索;
开发了首页的****信息流短剧推荐功能****。信息流主要特点就是 *低码率*(通过降低视频画质、降低视频采样率(60帧变为 25帧)等最终降低视频每秒传输的字节数);
- 因为考虑到 播放进度需要前端每秒汇报一次,请求速率很高。并且记录用户的播放进度。引入kafka 进行,并设计用户事件(UserEvent extends BaseEvent [唯一id,发送事件,用户])。 用户的所有行为请求进来,直接封装为事件。发送给kafka;(基本信息的封装由kafkaTemplate的拦截器进行统一设置。)
- 其他系统全部监听****kafka消息****,从而实现同步;
- *Redis数据缓存系统*:****缓存优先模式****(短剧信息、短剧点赞数量、短剧播放进度都直接查Redis,Redis没有再走回源逻辑即可), 所有和用户对接的高频的增删改查,查redis即可;
- 这些数据没有过期时间,考虑到 一旦数据过期要回源。MySQL由于自己同步速度慢,没有同步到数据,导致回源无数据,从而产生数据不一致问题。
- MySQL持久化系统:监听到消息以后。慢慢的进行数据保存;(Redis万一哪天没有数据,就回源MySQL查询)
- R:*用户高频操作的缓存命中率:几乎100%;基本不回源*。MySQL目前和Redis数据差异基本在秒级(由于目前量还没有太大);Redis 的线上故障时间(目前除了手动停机,Redis自己没停机过)。Redis 是 8核 32G 机器。 主从复制。无哨兵
- 为了实****现稳定转码,和人工兜底处理****。引入了 xxl-job,将转码任务交给 xxl-job 调度给某个机器,并且设置失败重试规则。 这样的好处是,即使多次失败后,任务还在xxl-job中有保存。手动修复相关问题后还可以继续手工启动任务;(主要核心思路,xxl-job原生只支持在控制台提交定时任务。现在需要AI审核通过以后,自动提交转码任务。所以默认robot机器人账号登录xxl-job,触发一个一次性任务启动)
链表 字典 跳跃表

AOF指令集 每秒一次
appendfsync everysec # 每秒同步1次(默认,推荐)
appendfsync always # 每次写命令都同步(最安全,性能损耗最大)
appendfsync no
宕机
缓冲区不足
高吞吐量、低延迟、*高可用(多副本机制)*
多消费者模型
消息可靠
kafka最终一致性

注册中心 配置中心
服务发现
服务上线自动注册到注册中心,客户端去注册中心获取对方微服务地址
@EnableXxxx 系列 @EnableCache @EnableTransationManagement
接口可以有多实现,。 抽象类单继承
Set 无需不重复 List 有序重复
select count(*) from user group by age in having (12,30) 差不多就这些
主键一定唯一,唯一不一定主键
explain
手动 commit ; 异常调用 rollback;
ACID、可能存在;具体过期策略;
底层就是 setnx ex 命令
加锁 删锁 原子性 锁续期 锁粒度不能太粗
kafka 就是 mq
消息幂等性 业务保证。 识别消息唯一id,做防重复处理
发送一个重试队列中 重试
tail -f grep|“关键字”
ping
线程池 通过创建合适索引优化为行锁
短信api 系统会根据是否有回调 进行代码层面的重试
try-with-resource 避免内存泄露
其他就是阿里开发手册嵩山版
你就说了解就行


定位
- 用
ps -ef | grep 服务进程名或jps(Java 服务)确认进程是否存在,是否有异常重启(结合操作系统日志/var/log/messages或dmesg查看是否被 OOM 杀死)。
*JVM——jstack*
- 用
jstack <进程ID>生成线程栈快照,搜索服务的业务线程(如 Tomcat 的http-nio-xxx线程、自定义线程池线程)。 - 重点关注状态为
BLOCKED(阻塞等待锁)、WAITING(无限期等待,如Object.wait())、TIMED_WAITING(超时等待,如Thread.sleep())的线程:- 若大量线程
BLOCKED,查看是否在竞争同一把锁(如静态方法锁、单例对象锁),定位到具体代码行(栈信息会显示类和方法)。 - 若线程
WAITING在java.net.SocketInputStream.read,说明在等待外部服务(如数据库、第三方 API)响应,可能是依赖超时或未返回。 - 若线程卡在
java.io.FileOutputStream.write,可能是日志文件写入阻塞(如磁盘满、权限不足)。
- 若大量线程
skywalking也可以
*垃圾回收*
- 用
jstat -gc <进程ID> 1000监控 GC 情况:若FGC频繁(每秒多次)且FGCT时间长(如每次几百毫秒),说明内存不足导致 GC 停顿,服务无法处理请求。 - 用
jmap -heap <进程ID>查看堆内存配置(如新生代、老年代大小),确认是否因堆配置过小导致频繁 GC。 - 用
jconsole或jvisualvm连接服务,实时查看线程状态、内存使用、GC 活动,定位阻塞点。
并行一起做,并发一个人做多个任务




反序列化的核心是:****读取序列化格式的数据(JSON/XML/ 二进制),并根据特定规则将其转换为编程语言中的对象****。具体步骤通常是:
- 读取序列化数据(从文件、网络流、请求体等)。
- 根据数据格式(如 JSON)选择对应的解析器(如 Jackson、Gson)。
- 指定目标对象类型,解析器将数据映射为该类型的实例。
****在 Spring Boot 中通过******\*@RequestBody\******实现反序列化***
在 Spring Boot 的 RESTful 接口中,客户端发送的 JSON 数据会通过 HTTP 请求体传递,服务端通过@RequestBody注解自动完成*****JSON→Java 对象*****的反序列化,底层由 Jackson 库实现。
****1. 准备实体类(目标对象)****
首先定义与 JSON 数据结构匹配的 Java 类:
*泛型允许我们定义类、接口或方法时,指定一个类型参数,在具体使用时再确定实际类型。*
- java.nio.file 包及其相关包 java.nio.file.attribute 为文件 I/O 和访问默认文件系统提供了全面支持。虽然该 API 包含许多类,但只需关注少数几个入口点即可。因此 API 非常直观且易于使用。
- 如何学习?
- Path 类:路径、路径操作、相对/绝对路径
- Files 类:文件操作共有的基本概念、文件检查、删除、复制和移动
*1. 通过****\*Executors\*****工具类快速创建(常用)*
****固定大小线程池**** ***\*newFixedThreadPool\****
****(2) 缓存线程池**** ***\*newCachedThreadPool\****
****(3) 单线程池**** ***\*newSingleThreadExecutor\****
****(4) 定时任务线程池**** ***\*newScheduledThreadPool\****
****2. 直接使用******\*ThreadPoolExecutor\******手动创建(推荐,更灵活)***
****1. CPU 密集型任务****
- ****特点****:任务主要消耗 CPU 资源(如计算、排序、加密),几乎无等待时间。
- ****线程数设置****:≈CPU 核心数(或 CPU 核心数 + 1)。
- ****原因****:CPU 核心数是同时能执行的最大线程数,过多线程会导致上下文切换,反而降低效率。
****2. IO 密集型任务****
****特点****:任务包含大量 IO 等待(如数据库查询、网络请求、文件读写),CPU 大部分时间处于空闲状态。
****线程数设置****:≈CPU 核心数 ×2(或 CPU 核心数 /(1 - 阻塞系数))。
****原因****:当一个线程等待 IO 时,CPU 可调度其他线程执行,充分利用 CPU 资源。“×2” 是经验值,本质是让 CPU 在 IO 等待期间不空闲。
*****Spring*****是整个生态的核心框架,提供基础功能;
*****Spring MVC*****是 Spring 框架的一个模块,专注于 Web 开发;
*****Spring Boot*****是基于 Spring 框架的快速开发工具,简化配置。
****1. Spring(Spring Framework)****
- ****定位***:Java 开发的**核心基础框架***,提供依赖注入(DI)、面向切面编程(AOP)等核心特性。
- ****核心功能****:
- ****IoC 容器****:管理对象的创建和依赖(BeanFactory、ApplicationContext);
- ****AOP****:实现日志、事务、权限等横切逻辑;
- ****事务管理****:统一的事务控制(声明式 / 编程式);
- ****数据访问****:整合 JDBC、ORM 框架(MyBatis、Hibernate)。
- ****特点****:功能全面但配置繁琐(需 XML 或注解配置),需手动整合各模块。
****2. Spring MVC****
- ****定位***:Spring 框架的**Web 模块***,基于 MVC 设计模式的请求驱动型框架。
- ****核心功能****:
- 处理 HTTP 请求(Controller、RequestMapping);
- 请求参数绑定、视图解析(JSP/Thymeleaf);
- 拦截器、异常处理;
- 与 Spring 核心无缝集成(依赖注入、AOP)。
- ****应用场景****:开发传统 Web 应用或 RESTful API。
- ****特点****:需手动配置 DispatcherServlet、视图解析器等组件。
****3. Spring Boot****
- ****定位***:**Spring 的快速开发脚手架***,简化 Spring 应用的搭建和配置。
- ****核心功能****:
- ****自动配置****:根据依赖自动配置组件(如引入 spring-boot-starter-web 则自动配置 Spring MVC);
- ****起步依赖****:整合常用依赖(如 spring-boot-starter-web 包含 Spring MVC、Tomcat 等);
- ****嵌入式容器****:内置 Tomcat/Jetty,无需部署 WAR 包;
- ****Actuator****:监控应用健康状态、指标。
- ****特点****:“约定优于配置”,减少 XML / 注解配置,快速开发独立运行的 Spring 应用。
*一段时间*
*SELECT COUNT(*) AS total_likes*
*FROM likes*
*WHERE created_at >= ‘2023-10-01 00:00:00’*
*AND created_at < ‘2023-11-01 00:00:00’;*
spring AI Alibaba
*业务*
生产者异步发送
队列多分区
手动提交消费的偏移量
唯一标识 有的
内只取交集 用null 表示
range 范围ref 非主eqref index system ccollection map
hashmap hashmap concurrenthashmap
高级 for 这种也说下
获取 key 的 set 集合通过迭代器遍历 set 获取
直接 get
hash 碰撞 的时候
nacos openfeign sentinel gateway
配置中心和注册中心
检查服务名 @feignclient 上的注解是否与控制器保持一致 可以了
版本回退 git reset
让你说流程呢 直接说流程就行了下面我给你写好了
核心线程数 不够的话放阻塞队列 队列满了继续创建线程执行任务
五个 默认的拒绝跑出异常 拒绝不跑出异常 拒绝等待时间最长的任务 调用主程序的 自定义拒绝策略
20251121面试记录

先去开放平台申请–获取对应的key配置在项目中—本地项目那个公钥访问第三方的API
先说explain 再说说字段 type key key_len rows extra[using filesort]
MVCC redolog undolog binlog 实现事务的控制
基于kafka的最终一致性 解耦 A–执行完–发消息 B消费消息 并修改状态
基于seata的分布式事务解决方案
JVM: 就是虚拟机 分了三个子系统 类加载子系统 运行时数据区子系统 执行

用arthas 看 阿尔萨斯 配合 jstack 导出 堆的dump日志 查看 GC信息
高并发: 缓存 异步 队列
高可用: 熔断 降级 限流
end