100快猫短剧
简历写法
当前市场:
微信小程序一堆的短剧、剧场类项目;这类项目唯一盈利点(付费解锁全集、月度/年度会员); 靠投广告,吸引用户看,开通付费
应用市场一堆 短剧、剧场类项目;App的盈利点
(1) 大量的用户看广告,收广告的钱
(1) 先做一个简单的自我介绍,说一下最近的项目
面试官你好。Xxxxx
- 最近项目、项目业务、业务技术(目的:给面试官感觉项目不错、技术栈挺ok、能问很多点)
做了什么项目,项目技术栈(主要用了boot/cloud/缓存/kafka),主要有哪些模块,自己做了哪些模块。模块的功能。功能的特色
胖猫短剧平台是一个基于微服务架构的短视频内容分发平台,专注于短剧内容的创作、审核、发布、播放与用户互动。系统采用RuoYi-Cloud脚手架构建,集成了工作流引擎、AI审核、视频处理、消息队列等现代化技术栈。
1.介绍!!(背诵)
最近项目:最近做了一个短剧项目,项目主要功能有短剧审核、短剧发布、App首页信息流刷剧、用户行为系统、会员系统等。
- 我负责了 短剧审核的整个流程(上架上传审核通过等流程)的开发:
整个审核是由Camunda流程引擎驱动,主要完成短剧发布后的Ai审核任务、视频信息流/画质流转码任务。这些任务为了稳定调度,还引入了xxl-job。还涉及到 AI大模型在审核方面的使用,以及腾讯云VOD系统的转码以及可靠通知流程
还做了App首页响应短剧数据请求接口的设计和开发;主要涉及到缓存的使用,使用之后大幅度提升性能。
最后负责了用户交互系统的整个开发流程(短剧点赞、收藏、评论、评论点赞、播放记录、播放进度等…),特色:将用户交互行为系统(互动服务)抽取成事件模式,每一种用户行为事件,都由Kafka进行统一保存,内容服务、互动服务、用户服务等服务模块来消费Kafka消息。完成数据库数据和缓存数据的最终一致性。缓存进行特别的设计(数据只看缓存,数据库相当于备份)。以前都是先读缓存,缓存没有就查库。我们现在由于用户互动行为频率太高了,所以全部的操作都去缓存中操作,由数据库进行同步。整个的一致性同步是靠 Kafka 消息消费抵达,我们进行双写。
STAR话术()
STAR:
S:需要开发开发完整的短剧上传-审核-转码-发布流程
整个审核是由Camunda流程引擎驱动,主要完成短剧发布后的Ai审核任务、视频信息流/画质流转码任务。这些任务为了稳定调度,还引入了xxl-job。还涉及到 AI大模型在审核方面的使用,以及腾讯云VOD系统的转码以及可靠通知流程
T:主要AI审核和对接腾讯云视频转码平台
A:
本地部署ollama,使用deepseekr1基本模型,基于提示词模板,进行结构化输出指定的json;
判断正向是否合法,负面是否不合法
- json结构:二分类:{negative: 0.7, positive:0.3}, {sad: 0.666, happy: 0.217, xxx}
为了实现稳定转码,和人工兜底处理。=================================================================引入了 xxl-job,将转码任务交给 xxl-job 调度给某个机器,并且设置失败重试规则。 这样的好处是,即使多次失败后,任务还在xxl-job中有保存。手动修复相关问题后还可以继续手工启动任务;(主要核心思路,xxl-job原生只支持在控制台提交定时任务。现在需要AI审核通过以后,自动提交转码任务。所以默认robot机器人账号登录xxl-job,触发一个一次性任务启动)
使用轮询机制,每10秒(*2)获取 vod 的转码结果消息。 只要看到转码成功的状态,提取信息流和画质流分别对应的转码结果,特别是画质流,要从结果中基于视频的 height 分辨出 各种分辨率视频对应的url地址
R:(可观测出的指标都可以描述)
- 最终基于线上的Prometheus+Grafana的整个监控系统反应。视频转码任务的调度成功率(成功次数/总次数)保持在 90% 以上。基本上3次以内重试,保证99% 都能转码成功。可能网络或者云厂商系统故障导致的 需要人工介入的比例下降很多。
还做了App首页响应短剧数据请求接口的设计和开发;主要涉及到缓存的使用,使用之后大幅度提升性能。
最后负责了用户交互系统的整个开发流程(短剧点赞、收藏、评论、评论点赞、播放记录、播放进度等…),特色:将用户交互行为系统(互动服务)抽取成事件模式,每一种用户行为事件,都由Kafka进行统一保存,内容服务、互动服务、用户服务等服务模块来消费Kafka消息。完成数据库数据和缓存数据的最终一致性。缓存进行特别的设计(数据只看缓存,数据库相当于备份)。以前都是先读缓存,缓存没有就查库。我们现在由于用户互动行为频率太高了,所以全部的操作都去缓存中操作,由数据库进行同步。整个的一致性同步是靠 Kafka 消息消费抵达,我们进行双写。
二、
- S:为了应对视频类应用的用户高频行为操作场景(主要是播放进度、点赞、收藏等一些用户行为)
- T:我们需要开发全用户事件感知系统
- A:
- 因为考虑到 播放进度需要前端每秒汇报一次,请求速率很高。并且记录用户的播放进度。引入kafka 进行血风田谷,并设计用户事件发送消息(UserEvent extends BaseEvent [唯一id,发送事件,用户])。 用户的所有行为请求进来,直接封装为事件。发送给kafka;(基本信息的封装由kafkaTemplate的拦截器进行统一设置。)
- 其他服务模块监听kafka消息,从而实现同步;
- Redis数据缓存系统:缓存优先模式(短剧信息、短剧点赞数量、短剧播放进度都直接查Redis,Redis没有再走回源逻辑即可), 所有和用户对接的高频的增删改查,查redis即可;
- 这些数过期时间为24h,考虑到 一旦数据过期要回源。MySQL由于自己同步速度慢,没有同步到数据,导致回源无数据,从而产生数据不一致问题。
- MySQL持久化系统:监听到消息以后。慢慢的进行数据保存;(Redis万一哪天没有数据,就回源MySQL查询)
- R:实现了最终一致性MySQL目前和Redis数据差异基本在秒级(由于目前量还没有太大);用户高频操作的缓存命中率:几乎100%;基本不回源。Redis 的线上故障时间(目前除了手动停机,Redis自己没停机过)。Redis 是 8核 32G 机器。 主从复制。无哨兵
面试问的大范围:
流程引擎用法
Xxl-job 用法
Ai整合使用流程
信息流/画质流,转码流程
腾讯云VOD系统,
高性能接口: 缓存、异步、排队
Kafka
最终一致性、Raft
2.重难点/亮点
面试官:你就说一下,你这个项目中你有遇到哪些难点问题吗?怎么解决的?
难点:视频转码任务;;xxl-job的二次开发、腾讯云事件的解析
重点:保证首页短剧的接口如何高性能;
1. 视频转码
由于腾讯云视频转码是一个后台任务,不一定什么时候执行完。我们和腾讯云转码的联动是由xxl-job进行驱动。视频发布以后,启动转码任务,这个转码任务提交给xxl-job进行调度;
1.我们对xxl-job 做了二次改造;
由于xxl-job的任务,默认是在他的控制台进行手动配置然后定时触发。我们现在需要的是,视频一上传,自动给xxl-job提交任务,调用vod转码,因此需要完成自动提交任务功能
需要对接口进行分析构造请求
所以我们先在 xxl-job 中开通一个 robot 账号。模拟机器人登录xxl-job。然后模拟给xxl-job 发请求(需要分析xxl-job-admin 哪些功能都发什么请求,需要解析出来,
比如: 
1 | |
构造对应的请求数据,然后模拟后台操作)。 去启动一个转码任务。转码任务被调度以后, 会给腾讯云提交两个任务流,分别是信息流任务和画质流任务。信息流主要低码率视频,通过网络能快速传输,方便用户上下滑动切换的时候,视频可以流畅播放。画质流主要是多画质转码(480p、720p、1080p)。 任务流什么时候运行完不一定。
用xxl-job的好处,调度的任务,在控制台有手动触发的方式。提供了手动补偿的方式。
2.我们需要获取腾讯云转码结果
使用腾讯云可靠消息模式(腾讯云每次完成的事件,会保存到他自己的队列中),需要我们客户端自己连上腾讯云拉取对应的事件。确认消费后,给腾讯云回复ok;
消息的获取: 需要使用轮询(每隔3s拉取腾讯云的所有事件),一直到拉取到当前转码视频对应的事件,需要解包腾讯云的数据(数据层级关系比较深,分析起来有点麻烦),解析到对应数据后,要提交到转码后的视频流地址,统一收集所有地址,去数据库批量保存转码后的数据。
1 | |
(腾讯云一堆事件、所有的视频上传、删除、修改, 启动任务流、任务流状态变化…) 我们主要感知到信息流和画质流的任务状态变化。通过知道 status = FINISH 且 事件对应的 fileId = 当前视频。就相当于拿到数据了
解完数据就无需再次轮询。就终止获取事件了。
VOD:视频点播;保存腾讯云转码后的视频url地址。能开启*CDN加速,让用户访问腾讯云最近的服务器获取到数据
难点使用 Camunda
参考话术:
视频审核是一个多阶段的流程:
AI审核–>视频内容审核–>人工审核–>审核结果汇总
使用 Camunda 的目的是:
把复杂流程可视化
状态和节点可追溯
人工审核可以暂停/回退
多个审核结果汇总更清晰
如果不用工作流,自己维护状态机会非常混乱。
2. App首页端(重点)
高性能接口(缓存、异步)、 自定义切面
我们参与编写了几个核心的高性能接口,并进行对应压力测试,以满足要求(首页 95% 响应时间 150ms 以内, 99% 要求响应时间 300ms以内)
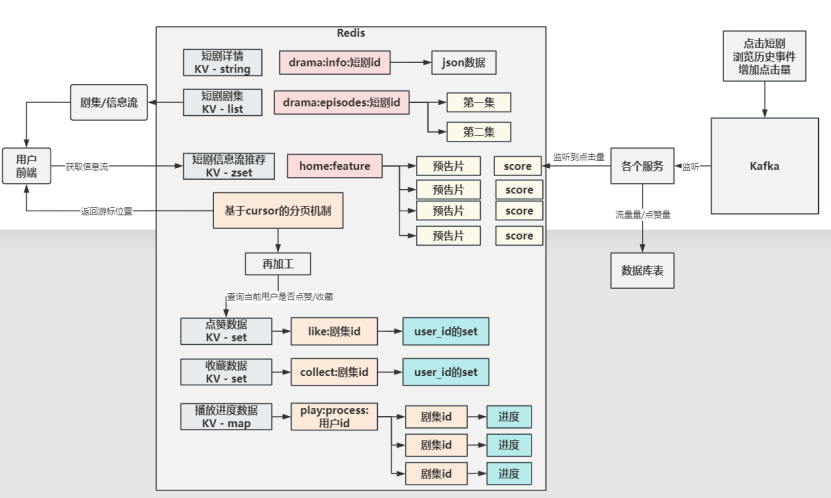
1. 首页推荐短剧信息流:
特色redis zset数据 +前后端配合使用cursor分页 + 定时任务给缓存上数据 + 异步线程池
由于这个接口第一次找数据库要的数据很多,第一次必须开启异步多线程同时获取各种数据
所有短剧都是上缓存的。Redis中维护了缓存列表;
每天晚上xxl-job定时任务调度给某一个机器,把全量短剧上线到缓存中(分页查询数据库保存数据到redis);
所有短剧实际上在一个 zset 集合中。 每个短剧的分数目前就是点赞量,点赞是一个用户事件。点击以后会发送kafka消息,我们收到消息会更新缓存的同时,更新数据库。
用户获取短剧内容分页查询,但是分页不走数据库,我们使用redis对list/zset/set 提供的 zrange/cursor(区间访问办法)
实现的分页。Cursor 有一个特点,不是说要10条redis就返回给用户10条。用户本质上是要新的一些数据,不一定返回10条,具体客户端此次请求要到的所有首页短剧信息流条目有多少以服务端为准。
重点:所有的数据都上缓存,缓存使用zest结构(redis需要复习)
,使用cursor的方式处理前端的分页查询。 查询完成,会给前端返回新的cursor位置,前端下一次发请求带上新位置,从这个位置开始获取一页数据; 缓存数据什么时候会更新?(主动/被动更新模式)
集合中数据的变化有两种,暂时没有个性化推荐
新发短剧,立即更新缓存
每晚定时任务,更新短剧缓存
2. 短剧详情:(详情页)
特色:缓存切面(缓存各大问题方案 + 分布式锁 全部集成) + Redisson
演员、介绍、图片…
缓存逻辑,短剧详细信息默认先查缓存,缓存中没有就准备回源。为了解决缓存的问题(穿透、击穿、雪崩)引入了一系列方案
3. 短剧剧集列表:每个短剧所有集信息(列表页)
缓存逻辑,短剧详细信息默认先查缓存
4. 【自定义】:抽取了缓存注解和缓存切面
我们抽取了两个通用的功能切面和注解:缓存注解和分布式锁注解
@CacheData 自定义注解: Spring Cache 提供的缓存注解,仅仅是简单的把数据放到缓存。没有 布隆过滤器、分布式锁、穿透、击穿、雪崩的解决方案
1 | |
@RedisLock(key=”lock”) 自定义注解:
redis设计模型
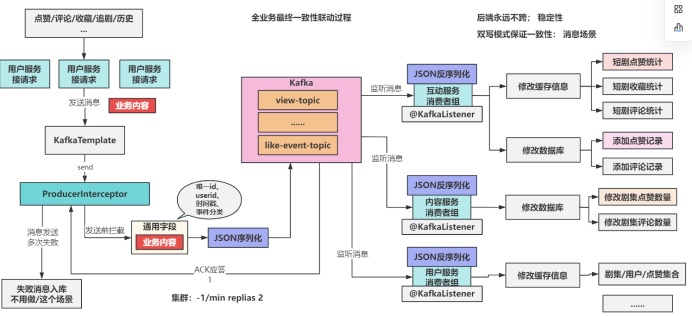
3. 互动服务(两点)
在这一个模块,我们构建一个全用户事件感知系统,实现的是最终一致性方案,针对性的设计了缓存数据模型,并且缓存优先进行读写
观看期间产生的所有用户事件: 由消息队列实现最终一致性进行处理。
用户事件是一个高频操作:单说播放进度,就是前端每秒会给我们汇报进度。高频操作。

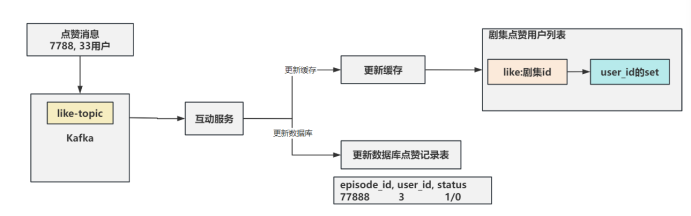
1. 点赞/取消
1. 短剧观看历史(点进短剧)
2. 收藏/取消
3. 评论
4. 评论点赞
流程
1 | |
流程说明:
- 异步响应: 用户点赞后立即返回成功,不等待消费完成(降低响应时间)
- 并行消费: user-service和interaction-service同时消费消息,互不阻塞
- 最终一致性: 数据库持久化 + Redis缓存最终同步
- 幂等性保证:
- 数据库: 通过唯一索引 + UPDATE操作保证幂等
- Redis Set: sadd/srem操作天然幂等
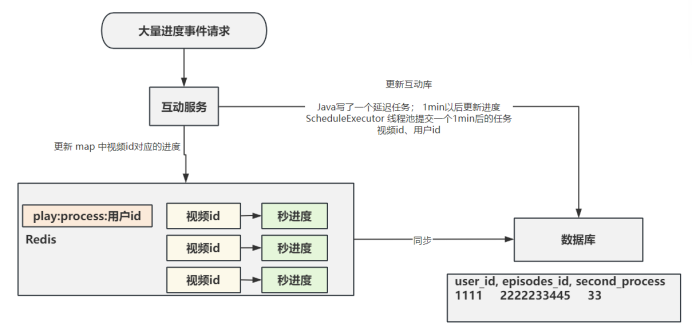
5. 播放进度
(1) 收到播放进度事件以后,每个用户哪个视频播放到哪里,在redis有维护进度列表(value是一个map类型);先更新缓存,然后更新数据库
ScheduledExecutorService 是 Java 提供的更强大的延时任务实现方式。它可以创建一个线程池来执行延时任务,适用于大量异步任务的场景。示例如下:
1 | |
其他各种事件
6. 所有的数据模型设计
互动服务的最大难点在于:
构建一套事件流的感知架构的系统。事件抵达以后,各种微服务收到消息,会修改对应的缓存和数据库
(缓存优先模式)整个互动服务,所有数据的读写都是在缓存中进行。数据库反而现在需要同步缓存。我们并不去做数据库同步缓存的操作,而是构建稳定消息系统。消息抵达后,缓存和数据库是同时双写模式。实现的最终一致性效果。
缓存中各种数据模型的设计。 设计一个合理的,易于修改的数据模型;(JSON不能乱用)
7. MySQL支持全文检索(轻量级,数据量小)
TEXT字段,建立 FULL_TEXT 索引; 玩具版
4.每个点的技术细节
**1.**流程引擎用法
Camunda主要两种用法。
1) Docker启动Camunda服务,Camunda提供REST API,我们应用和 Camunda 进行HTTP 交互
2) 在****SpringBoot 中整合 Camunda。 能用Camunda提供的SDK一堆**API;(我们用)**
a. RepositoryService 主要做流程部署相关
b. RuntimeService 主要做流程启动运行相关
c. TaskService 主要做任务领取、完成相关
d. HistoryService 主要做历史流程、历史变量相关
e. xxxService
核心:
业务流程的设计和推进(网关【排他、包含、并行】)
业务推进期间共享一些数据,数据使用流程变量;
(1) 为什么用流程变量而不用redis共享数据呀?
① 主要因为用流程变量,即使流程结束还可以查询之前的历史,溯源
②redis可能出现删除问题
- Camunda高阶: OA会签、子/父流程、变换流转…
重难点: API
2. Xxl-job 用法
3. Ai整合使用流程
AI大模型是用来做审核的。
提示词优化 + 模板化输出; 判定违禁词,方便给人工审核一个提示。
4. 信息流/画质流,转码流程
5. 腾讯云VOD系统,
6. 高性能接口: 缓存、异步、排队
1)、Redis(持久化、内存淘汰、基本数据类型)
2)、Redisson(分布式锁机制、看门狗(提交的一个异步延迟任务进行的续期)、 分布式锁原理【setnxex】)
3)、缓存整套流程、数据一致性如何保证
- 缓存+数据库
1)、失效模式/增强版失效(延迟双删)
2)、双写模式
3)、互动服务中全消息的最终一致性
4)、异步
1)、CompletableFuture
2)、ThreadPoolExecutor; 线程池7大参数
7. Kafka
(1) 集群原理: topic、partition、ISR
(2) 消息可靠性:
① 发送者ack模式
0:kafka收到消息给生产者回复ok1:kafka leader持久化后回复ok: 我们用这个-1:Kafka leader + isr 都持久化 回复 ok
② 消费者 手动ack
收到消息,并执行成功,回复给kafka ok。提交偏移量
③ *Kafka***本身: 集群(topic多分区,每个分区的leader在不同机器,其他机器有备份)。Leader来接收所有消息的CRUD
(3) 消费模式:
① 点对点:同一个消费者组,一个消息只能给同组的一个人
② 发布/订阅:不同消费者组,一个消息会广播给所有消息组
(4) 消息重复、消息顺序、消息丢失
① 消息重复:幂等性(消费者自己处理)
典型情况:**重平衡(消费者数量发生变化)**;什么时候发生,发生后kafka怎么做
② 消息顺序:
单发送者 + 主题单分区 + 单消费者单线程(必定有顺序)其他办法:分布式锁 + redis维护消息消费顺序
③ 消息丢失:
消息可靠性: 发送者Ack模式、(可靠回调)消费者手动ACK
(5) Kafka的刷盘机制。
① Kafka把消息写到页缓存就结束。不要修改刷盘策略(会影响吞吐量)
② Kafka推荐利用ISR(多副本机制进行备份即可)
8. 最终一致性、Raft
9. 项目架构点: 每个项目都长这样。
(1) MySQL读写分离;shardingsphere
(2) Redis 主从同步 不加哨兵;(数据量没那么大)
① 要求客户端连接哨兵;
(3) Kafka 3台机器,多节点集群。(副本数量最多为3)
(4) Minio
(5) Xxl-job
(6) ShardingProxy
(7) 日志系统: ElasticSearch + Kibana + Filebeat(收集日志)
(8) 监控系统: Prometheus(时序数据库) + grafana
=======================基本都长这样=======================
自己按照简历模板:
- 写一个自己简历里面的项目介绍;(不宜太多,重点亮眼)
(1) 项目介绍
(2) 项目技术栈
(3) 个人职责
(4) 个人负责模块的技术特色
- 个人介绍 + 项目介绍: (1000字~1500字)
(1) 控制口播稿 3-7分钟
(2) 提取点,就是面试官的拷打范围
背稿子,背面试场景题
互动服务的最大难点在于:
构建一套事件流的感知架构的系统。事件抵达以后,各种微服务收到消息,会修改对应的缓存和数据库
(缓存优先模式)整个互动服务,所有数据的读写都是在缓存中进行。数据库反而现在需要同步缓存。我们并不去做数据库同步缓存的操作,而是构建稳定消息系统。消息抵达后,缓存和数据库是同时双写模式。实现的最终一致性效果。
缓存中各种数据模型的设计。 设计一个合理的,易于修改的数据模型;(JSON不能乱用)