40Java、基础
Java基础
说一下Java的特点
主要有以下的特点:
- 平台无关性:Java的“编写一次,运行无处不在”哲学是其最大的特点之一。Java编译器将源代码编译成字节码(bytecode),该字节码可以在任何安装了Java虚拟机(JVM)的系统上运行。
- 面向对象:Java是一门严格的面向对象编程语言,几乎一切都是对象。面向对象编程(OOP)特性使得代码更易于维护和重用,包括类(class)、对象(object)、继承(inheritance)、多态(polymorphism)、抽象(abstraction)和封装(encapsulation)。
- 内存管理:Java有自己的垃圾回收机制,自动管理内存和回收不再使用的对象。这样,开发者不需要手动管理内存,从而减少内存泄漏和其他内存相关的问题
劣势:
(1)性能: 虽然靠JVM优化了很多性能,但相比C++,Rust这种原生编译语言,还是有一些性能开销.
(2)启动时间长: 在微服务场景下, 启动可能不如Go快.
(3)语法繁杂: 样板代码多,在没有lambda表达式之前更麻烦, 有了之后相比Python还是不够简洁.
(4)内存消耗: JVM本身占内存,对资源有限的环境不太友好
(6)开发效率低: 相比于动态语言如Python, Java需要更多代码,编译过程也可能拖慢开发节奏.
JVM、JDK、JRE三者关系?
JVM是Java虚拟机,是Java程序运行的环境。
JDK是Java开发工具包,是开发Java程序所需的工具集合。它包含了JVM、编译器(javac)、调试器(jdb)等开发工具,以及一系列的类库(如Java标准库和开发工具库)。JDK提供了开发、编译、调试和运行Java程序所需的全部工具和环境。
JRE是Java运行时环境,是Java程序运行所需的最小环境。它包含了JVM和一组Java类库,用于支持Java程序的执行。JRE不包含开发工具,
为什么Java解释和编译都有?
编译性:
- Java源代码首先被编译成字节码,JIT 会把编译过的机器码保存起来,以备下次使用。
解释性:
- JVM中一个方法调用计数器,当累计计数大于一定值的时候,就使用JIT进行编译生成机器码文件。否则就是用解释器进行解释执行,然后字节码也是经过解释器进行解释运行的。
所以Java既是编译型也是解释性语言,默认采用的是解释器和编译器混合的模式。
** 编译型语言和解释型语言的区别?**
编译型语言和解释型语言的区别在于:
- 编译型语言:在程序执行之前,整个源代码会被编译成机器码或者字节码,生成可执行文件。执行时直接运行编译后的代码,速度快,但跨平台性较差。
- 解释型语言:在程序执行时,逐行解释执行源代码,不生成独立的可执行文件。通常由解释器动态解释并执行代码,跨平台性好,但执行速度相对较慢。
八种基本的数据类型
Java支持数据类型分为两类: 基本数据类型和引用数据类型。
基本数据类型共有8种,可以分为三类:
- 数值型:整数类型(byte、short、int、long)和浮点类型(float(4字节)、double)
- 字符型:char(一般2字节)
- 布尔型:boolean
数据类型转换方式你知道哪些?
- 自动类型转换(隐式转换):当目标类型的范围大于源类型时,Java会自动将源类型转换为目标类型,不需要显式的类型转换。例如,将
int转换为long、将float转换为double等。 - 强制类型转换(显式转换):当目标类型的范围小于源类型时,需要使用强制类型转换将源类型转换为目标类型。这可能导致数据丢失或溢出。例如,将
long转换为int、将double转换为int等。语法为:目标类型 变量名 = (目标类型) 源类型。 - 字符串转换:Java提供了将字符串表示的数据转换为其他类型数据的方法。例如,将字符串转换为整型
int,可以使用Integer.parseInt()方法;将字符串转换为浮点型double,可以使用Double.parseDouble()方法等。 - 数值之间的转换:Java提供了一些数值类型之间的转换方法,如将整型转换为字符型、将字符型转换为整型等。这些转换方式可以通过类型的包装类来实现,例如
Character类、Integer类等提供了相应的转换方法。
装箱和拆箱是什么?
装箱(Boxing)和拆箱(Unboxing)是将基本数据类型和对应的包装类之间进行转换的过程。
自动装箱主要发生在两种情况,一种是赋值时,另一种是在方法调用的时候。
赋值时
这是最常见的一种情况,在Java 1.5以前我们需要手动地进行转换才行,而现在所有的转换都是由编译器来完成。
方法调用时
当我们在方法调用时,我们可以传入原始数据值或者对象,同样编译器会帮我们进行转换。
Integer相比int有什么优点?
int是Java中的原始数据类型,而Integer是int的包装类。
Integer和 int 的区别:
- 基本类型和引用类型:首先,int是一种基本数据类型,而Integer是一种引用类型。基本数据类型是Java中最基本的数据类型,它们是预定义的,不需要实例化就可以使用。而引用类型则需要通过实例化对象来使用。这意味着,使用int来存储一个整数时,不需要任何额外的内存分配,而使用Integer时,必须为对象分配内存。在性能方面,基本数据类型的操作通常比相应的引用类型快。
- 包装类是引用类型,对象的引用和对象本身是分开存储的,而对于基本类型数据,变量对应的内存块直接存储数据本身。
- 自动装箱和拆箱:其次,Integer作为int的包装类,它可以实现自动装箱和拆箱。
- 空指针异常:另外,int变量可以直接赋值为0,而Integer变量必须通过实例化对象来赋值。
不管是读写效率,还是存储效率,基本类型都比包装类高效。
说一下 integer的缓存
Java的Integer类内部实现了一个静态缓存池,用于存储特定范围内的整数值对应的Integer对象。
默认情况下,这个范围是-128至127。当通过Integer.valueOf(int)方法创建一个在这个范围内的整数对象时,并不会每次都生成新的对象实例,而是复用缓存中的现有对象,会直接从内存中取出,不需要新建一个对象。
变量
成员变量和局部变量的区别
(1)语法形式:
成员变量 -> 属于类,可以被public,static,private等修饰符所修饰
局部变量 -> 在代码块或方法中定义的变量或者方法的参数,不能被访问控制修饰符以及static修饰
局部变量和成员变量都能被final所修饰
(2)存储方式:
局部变量 -> 栈内存
成员变量 -> 若被static修饰,则该变量是类变量,存储于元空间或永久代中,若没有用static修饰,则存储于堆内存中的,与前者用对象头关联.
(3)生命周期:
局部变量 -> 随方法的调用而产生,随方法调用结束而消亡
成员变量-> 随对象创建而存在,随对象被回收而消亡
(4)默认值:
局部变量 -> 不会自动赋值,因此需要在使用前手动赋值
成员变量 -> 没有final修饰时,会自动以类型的默认值来赋值.有final修饰时,必须显式赋值.
为什么成员变量有默认值?
成员变量存储在堆内存中,这些内存区域在分配前可能被其它数据占用过,若没有默认值机制,新创建的成员变量会直接复用这些残留的随机数据.
成员变量在运行时可以借助反射等方法赋值,但局部变量不行
静态变量有什么用
(1)什么是静态变量:
静态变量是被static关键字修饰的变量,可以被类的所有实例共享,无论一个类创建了多少个对象,它们都共享一份静态变量.
(2)静态变量如何访问:
通常是通过类名访问,也可以通过对象名访问(不推荐)
(3)静态变量一般会被final修饰成常量,这样做的好处
可见性保证
用final修饰后会加上写屏障,执行完写操作后将工作内存同步到主存,进而保证可见性.
防止误修改
用final修饰的静态变量,可以确保这些变量的值在初始化后不会被修改.
性能优化
static final修饰的成员变量在类加载的准备阶段赋值(确定)
静态变量的成员变量的访问不需要创建实例对象
面向对象

面向对象的设计原则你知道有哪些吗
面向对象编程中的六大原则:
- 单一职责原则(SRP):一个类应该只有一个引起它变化的原因,即一个类应该只负责一项职责。例子:考虑一个员工类,它应该只负责管理员工信息,而不应负责其他无关工作。
- 开放封闭原则(OCP):软件实体应该对扩展开放,对修改封闭。例子:通过制定接口来实现这一原则,比如定义一个图形类,然后让不同类型的图形继承这个类,而不需要修改图形类本身。
- 里氏替换原则(LSP):子类对象应该能够替换掉所有父类对象。例子:一个正方形是一个矩形,但如果修改一个矩形的高度和宽度时,正方形的行为应该如何改变就是一个违反里氏替换原则的例子。
- 接口隔离原则(ISP):客户端不应该依赖那些它不需要的接口,即接口应该小而专。例子:通过接口抽象层来实现底层和高层模块之间的解耦,比如使用依赖注入。
- 依赖倒置原则(DIP):高层模块不应该依赖低层模块,二者都应该依赖于抽象;抽象不应该依赖于细节,细节应该依赖于抽象。例子:如果一个公司类包含部门类,应该考虑使用合成/聚合关系,而不是将公司类继承自部门类。
- 最少知识原则 (Law of Demeter):一个对象应当对其他对象有最少的了解,只与其直接的朋友交互
重载与重写有什么区别?
重载是指在同一个类中定义多个同名方法,而重写是指子类重新定义父类中的方法。
抽象类和普通类区别?
- 实例化:普通类可以直接实例化对象,而抽象类不能被实例化,只能被继承。
- 方法实现:普通类中的方法可以有具体的实现,而抽象类中的方法可以有实现也可以没有实现。
- 继承:一个类可以继承一个普通类,而且可以继承多个接口;而一个类只能继承一个抽象类,但可以同时实现多个接口。
- 实现限制:普通类可以被其他类继承和使用,而抽象类一般用于作为基类,被其他类继承和扩展使用。
Java抽象类和接口的区别是什么?
两者的特点:
- 抽象类用于描述类的共同特性和行为,可以有成员变量、构造方法和具体方法。适用于有明显继承关系的场景。
- 接口用于定义行为规范,可以多实现,只能有常量和抽象方法(Java 8 以后可以有默认方法和静态方法)。适用于定义类的能力或功能。
两者的区别:
- 实现方式:实现接口的关键字为implements,继承抽象类的关键字为extends。一个类可以实现多个接口,但一个类只能继承一个抽象类。所以,使用接口可以间接地实现多重继承。
- 方法方式:接口只有定义,不能有方法的实现,java 1.8中可以定义default方法体,而抽象类可以有定义与实现,方法可在抽象类中实现。
- 访问修饰符:接口成员变量默认为public static final,必须赋初值,不能被修改;其所有的成员方法都是public、abstract的。抽象类中成员变量默认default,可在子类中被重新定义,也可被重新赋值;抽象方法被abstract修饰,不能被private、static、synchronized和native等修饰,必须以分号结尾,不带花括号。
- 变量:抽象类可以包含实例变量和静态变量,而接口只能包含常量(即静态常量)。
抽象类能加final修饰吗?
不能,Java中的抽象类是用来被继承的,而final修饰符用于禁止类被继承或方法被重写,因此,抽象类和final修饰符是互斥的,不能同时使用。
接口里面可以定义哪些方法?
- 抽象方法
抽象方法是接口的核心部分,所有实现接口的类都必须实现这些方法。抽象方法默认是 public 和 abstract,这些修饰符可以省略。
- 默认方法
默认方法是在 Java 8 中引入的,允许接口提供具体实现。实现类可以选择重写默认方法。
- 静态方法
静态方法也是在 Java 8 中引入的,它们属于接口本身,可以通过接口名直接调用,而不需要实现类的对象。
- 私有方法
私有方法是在 Java 9 中引入的,用于在接口中为默认方法或其他私有方法提供辅助功能。这些方法不能被实现类访问,只能在接口内部使用。
解释Java中的静态变量和静态方法
在Java中,静态变量和静态方法是与类本身关联的,而不是与类的实例(对象)关联。它们在内存中只存在一份,可以被类的所有实例共享。
静态变量
静态变量(也称为类变量)是在类中使用static关键字声明的变量。它们属于类而不是任何具体的对象。主要的特点:
- 共享性:所有该类的实例共享同一个静态变量。如果一个实例修改了静态变量的值,其他实例也会看到这个更改。
- 初始化:静态变量在类被加载时初始化,只会对其进行一次分配内存。
- 访问方式:静态变量可以直接通过类名访问,也可以通过实例访问,但推荐使用类名。
示例:
1 | |
静态方法
静态方法是在类中使用static关键字声明的方法。类似于静态变量,静态方法也属于类,而不是任何具体的对象。主要的特点:
- 无实例依赖:静态方法可以在没有创建类实例的情况下调用。对于静态方法来说,不能直接访问非静态的成员变量或方法,因为静态方法没有上下文的实例。
- 访问静态成员:静态方法可以直接调用其他静态变量和静态方法,但不能直接访问非静态成员。
- 多态性:静态方法不支持重写(Override),但可以被隐藏(Hide)。
1 | |
使用场景
- 静态变量:常用于需要在所有对象间共享的数据,如计数器、常量等。
- 静态方法:常用于助手方法(utility methods)、获取类级别的信息或者是没有依赖于实例的数据处理。
关键字
#Java 中 final 作用是什么?
final关键字主要有以下三个方面的作用:用于修饰类、方法和变量。
- 修饰类:当
final修饰一个类时,表示这个类不能被继承,是类继承体系中的最终形态。例如,Java 中的String类就是用final修饰的,这保证了String类的不可变性和安全性,防止其他类通过继承来改变String类的行为和特性。 - 修饰方法:用
final修饰的方法不能在子类中被重写。比如,java.lang.Object类中的getClass方法就是final的,因为这个方法的行为是由 Java 虚拟机底层实现来保证的,不应该被子类修改。 - 修饰变量:当
final修饰基本数据类型的变量时,该变量一旦被赋值就不能再改变。例如,final int num = 10;,这里的num就是一个常量,不能再对其进行重新赋值操作,否则会导致编译错误。
深拷贝和浅拷贝
#深拷贝和浅拷贝的区别?
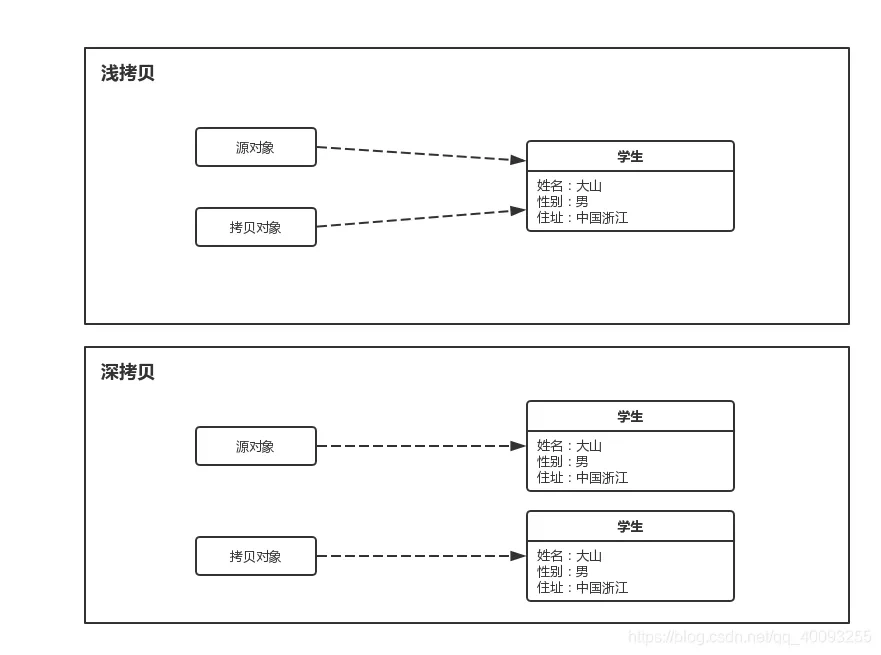
- 浅拷贝是指只复制对象本身和其内部的值类型字段,但不会复制对象内部的引用类型字段。换句话说,浅拷贝只是创建一个新的对象,然后将原对象的字段值复制到新对象中,但如果原对象内部有引用类型的字段,只是将引用复制到新对象中,两个对象指向的是同一个引用对象。
- 深拷贝是指在复制对象的同时,将对象内部的所有引用类型字段的内容也复制一份,而不是共享引用。换句话说,深拷贝会递归复制对象内部所有引用类型的字段,生成一个全新的对象以及其内部的所有对象。
#实现深拷贝的三种方法是什么?
在 Java 中,实现对象深拷贝的方法有以下几种主要方式:
实现 Cloneable 接口并重写 clone() 方法
这种方法要求对象及其所有引用类型字段都实现 Cloneable 接口,并且重写 clone() 方法。在 clone() 方法中,通过递归克隆引用类型字段来实现深拷贝。
使用序列化和反序列化
通过将对象序列化为字节流,再从字节流反序列化为对象来实现深拷贝。要求对象及其所有引用类型字段都实现 Serializable 接口。
手动递归复制
针对特定对象结构,手动递归复制对象及其引用类型字段。适用于对象结构复杂度不高的情况。
泛型
#什么是泛型?
泛型是 Java 编程语言中的一个重要特性,它允许类、接口和方法在定义时使用一个或多个类型参数,这些类型参数在使用时可以被指定为具体的类型。
泛型的主要目的是在编译时提供更强的类型检查,并且在编译后能够保留类型信息,避免了在运行时出现类型转换异常。
为什么需要泛型?
- 适用于多种数据类型执行相同的代码
如果没有泛型,要实现不同类型的加法,每种类型都需要重载一个add方法;通过泛型,我们可以复用为一个方法:
1 | |
- 泛型中的类型在使用时指定,不需要强制类型转换(类型安全,编译器会检查类型)
1 | |