HashMap
1.HashMap集合简介
HashMap基于哈希表的Map接口实现,是以key-value存储形式存在,即主要用来存放键值对。HashMap 的实现不是同步的,这意味着它不是线程安全的。它的key(一个)、value(多个)(HashTable不允许)都可以为null。此外,HashMap中的映射不是有序的。
JDK1.8 之前 HashMap 由 数组+链表 组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突**(两个对象调用的hashCode方法计算的哈希码值一致导致计算的数组索引值相同)**而存在的(“拉链法”解决冲突).JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(或者红黑树的边界值,默认为 8)并且当前数组的长度大于64时,此时此索引位置上的所有数据改为使用红黑树存储。
数据结构相关面试
1.面试题:HashMap中hash函数是怎么实现的?还有哪些hash函数的实现方式?
1 | |
2.面试题:当两个对象的hashCode相等时会怎么样?
1 | |
3.面试题:何时发生哈希碰撞和什么是哈希碰撞,如何解决哈希碰撞?
1 | |
4.面试题:如果两个键的hashcode相同,如何存储键值对?
1 | |
5.在不断的添加数据的过程中,会涉及到扩容问题,当超出临界值(且要存放的位置非空)时,扩容。默认的扩容方式:扩容为原来容量的2倍,并将原有的数据复制过来。
6.通过上述描述,当位于一个链表中的元素较多,即hash值相等但是内容不相等的元素较多时,通过key值依次查找的效率较低。而JDK1.8中,哈希表存储采用数组+链表+红黑树实现,当链表长度(阀值)超过 8 时且当前数组的长度 > 64时,将链表转换为红黑树,这样大大减少了查找时间。jdk8在哈希表中引入红黑树的原因只是为了查找效率更高。
简单的来说,哈希表是由数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的。如下图所示。
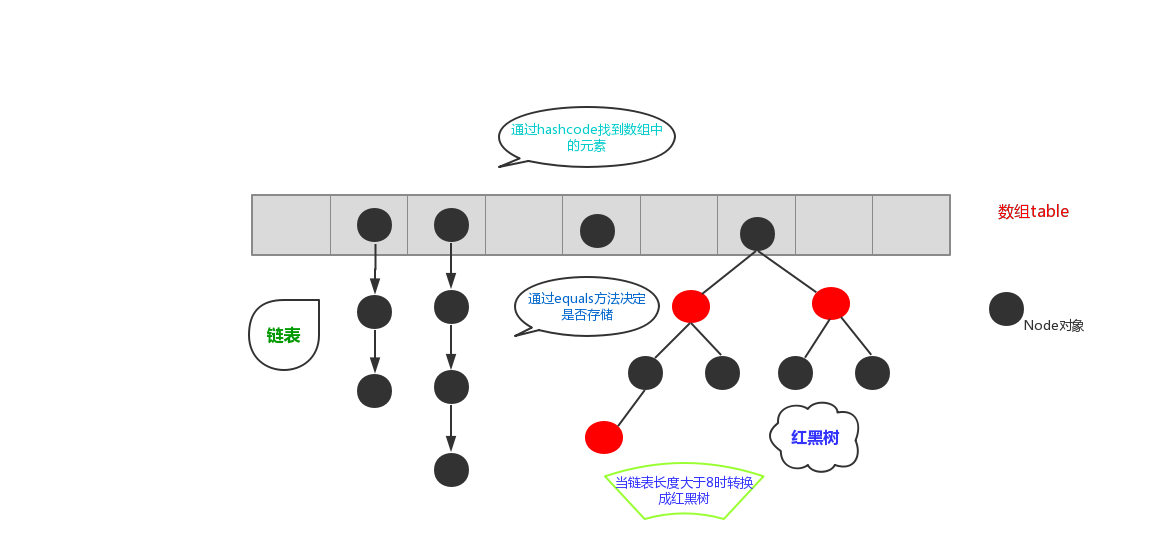
HashMap集合类的成员
4.1成员变量
1.序列化版本号
1 | |
2.集合的初始化容量( 必须是二的n次幂 )
1 | |
问题: 为什么必须是2的n次幂?如果输入值不是2的幂比如10会怎么样?
HashMap构造方法还可以指定集合的初始化容量大小:
1 | |
根据上述讲解我们已经知道,当向HashMap中添加一个元素的时候,需要根据key的hash值,去确定其在数组中的具体位置。 HashMap为了存取高效,要尽量较少碰撞,就是要尽量把数据分配均匀,每个链表长度大致相同,这个实现就在把数据存到哪个链表中的算法。
这个算法实际就是取模,hash%length,计算机中直接求余效率不如位移运算(这点上述已经讲解)。所以源码中做了优化,使用 hash&(length-1),而实际上hash%length等于hash&(length-1)的前提是length是2的n次幂。
为什么这样能均匀分布减少碰撞呢?2的n次方实际就是1后面n个0,2的n次方-1 实际就是n个1;
举例:
说明:按位与运算:相同的二进制数位上,都是1的时候,结果为1,否则为零。
因此,HashMap 容量为2次幂的原因,就是为了数据的的均匀分布,减少hash冲突,毕竟hash冲突越大,代表数组中一个链的长度越大,这样的话会降低hashmap的性能
如果创建HashMap对象时,输入的数组长度是10,不是2的幂,HashMap通过一通位移运算和或运算得到的肯定是2的幂次数,并且是离那个数最近的数字。
3.默认的负载因子,默认值是0.75
1 | |
4.集合最大容量
1 | |
5.当链表的值超过8则会转红黑树(1.8新增)
1 | |
问题:为什么Map桶中节点个数超过8才转为红黑树?
8这个阈值定义在HashMap中,针对这个成员变量,在源码的注释中只说明了8是bin(bin就是bucket(桶))从链表转成树的阈值,但是并没有说明为什么是8:
在HashMap中有一段注释说明: 我们继续往下看 :
TreeNodes占用空间是普通Nodes的两倍,所以只有当bin包含足够多的节点时才会转成TreeNodes,而是否足够多就是由TREEIFY_THRESHOLD的值决定的。当bin中节点数变少时,又会转成普通的bin。并且我们查看源码的时候发现,链表长度达到8就转成红黑树,当长度降到6就转成普通bin。
这样就解释了为什么不是一开始就将其转换为TreeNodes,而是需要一定节点数才转为TreeNodes,说白了就是权衡,空间和时间的权衡。
这段内容还说到:当hashCode离散性很好的时候,树型bin用到的概率非常小,因为数据均匀分布在每个bin中,几乎不会有bin中链表长度会达到阈值。但是在随机hashCode下,离散性可能会变差,然而JDK又不能阻止用户实现这种不好的hash算法,因此就可能导致不均匀的数据分布。不过理想情况下随机hashCode算法下所有bin中节点的分布频率会遵循泊松分布,我们可以看到,一个bin中链表长度达到8个元素的概率为0.00000006,几乎是不可能事件。所以,之所以选择8,不是随便决定的,而是根据概率统计决定的。由此可见,发展将近30年的Java每一项改动和优化都是非常严谨和科学的。
也就是说:选择8因为符合泊松分布,超过8的时候,概率已经非常小了,所以我们选择8这个数字。
小于6变回来
6.当链表的值小于6则会从红黑树转回链表
1 | |
7.当Map里面的数量超过这个值时,表中的桶才能进行树形化 ,否则桶内元素太多时会扩容,而不是树形化 为了避免进行扩容、树形化选择的冲突,这个值不能小于 4 * TREEIFY_THRESHOLD (8)
1 | |
8、table用来初始化(必须是二的n次幂)(重点)
1 | |
table在JDK1.8中我们了解到HashMap是由数组加链表加红黑树来组成的结构其中table就是HashMap中的数组,jdk8之前数组类型是Entry<K,V>类型。从jdk1.8之后是Node<K,V>类型。只是换了个名字,都实现了一样的接口:Map.Entry<K,V>。负责存储键值对数据的。
9、用来存放缓存
1 | |
10、 HashMap中存放元素的个数(重点)
1 | |
size为HashMap中K-V的实时数量,不是数组table的长度。
11、 用来记录HashMap的修改次数
1 | |
12、 用来调整大小下一个容量的值计算方式为(容量*负载因子)
1 | |
13、 哈希表的加载因子(重点)
1 | |
说明:
1.loadFactor加载因子,是用来衡量 HashMap 满的程度,表示HashMap的疏密程度,影响hash操作到同一个数组位置的概率,计算HashMap的实时加载因子的方法为:size(K-V的实时数量)/capacity(table 的长度length),而不是占用桶的数量去除以capacity。capacity 是桶的数量,也就是 table 的长度length。
loadFactor太大导致查找元素效率低,太小导致数组的利用率低,存放的数据会很分散。loadFactor的默认值为0.75f是官方给出的一个比较好的临界值。
当HashMap里面容纳的元素已经达到HashMap数组长度的75%时,表示HashMap太挤了,需要扩容,而扩容这个过程涉及到 rehash、复制数据等操作,非常消耗性能。,所以开发中尽量减少扩容的次数,可以通过创建HashMap集合对象时指定初始容量来尽量避免。
同时在HashMap的构造器中可以定制loadFactor。
1 | |
2.为什么加载因子设置为0.75,初始化临界值是12?
loadFactor越趋近于1,那么 数组中存放的数据(entry)也就越多,也就越密,也就是会让链表的长度增加,loadFactor越小,也就是趋近于0,数组中存放的数据(entry)也就越少,也就越稀疏。
如果希望链表尽可能少些。要提前扩容,有的数组空间有可能一直没有存储数据。加载因子尽可能小一些。
举例:
1 | |
所以既兼顾数组利用率又考虑链表不要太多,经过大量测试0.75是最佳方案
4.3成员方法
4.3.1增加方法
put方法是比较复杂的,实现步骤大致如下:
1)先通过hash值计算出key映射到哪个桶;
2)如果桶上没有碰撞冲突,则直接插入;
3)如果出现碰撞冲突了,则需要处理冲突:
a:如果该桶使用红黑树处理冲突,则调用红黑树的方法插入数据;
b:否则采用传统的链式方法插入。如果链的长度达到临界值,则把链转变为红黑树;
4)如果桶中存在重复的键,则为该键替换新值value;
5)如果size大于阈值threshold,则进行扩容;
end